
Vik Nagjee is the vice president of product at nference [Photo courtesy of nference]
Cloud computing can power quantum leaps in human health.
Vik Nagjee, nference
A state-of-the art platform that supports real world evidence (RWE) and health economics and outcomes research can enable breakthroughs at an unprecedented scale.
This is achieved by making the de-identified, transformed information contained within the electronic medical record (EMR) available for data science and analysis at the aggregate and patient level. Add multi-modal data sources such as imaging and electrocardiograms as well as novel data assets like digital pathology and omics data to enrich the EMR data to provide a truly longitudinal view of the patient, and you have the beginnings of a world-class platform.
The keys are privacy preservation, harnessing longitudinal data, data enrichment and a data science platform.
Privacy preservation and harnessing longitudinal data (including novel data assets)
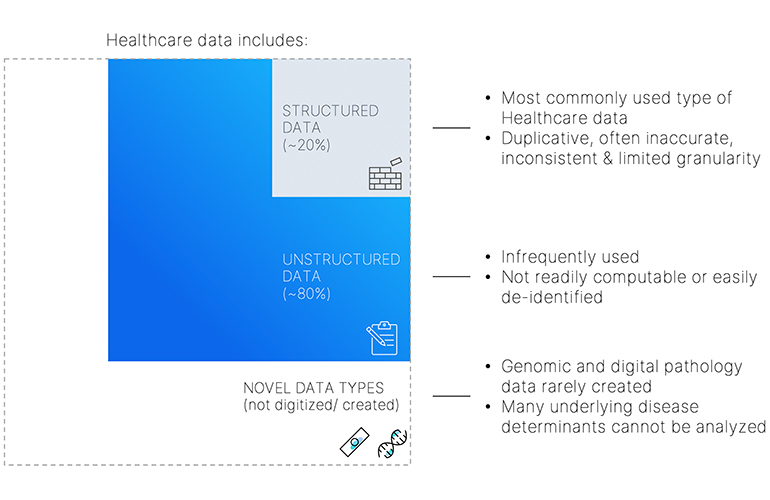
In order to be able to perform medical device/drug design/clinical trials research, the most valuable data is based on RWE, which is harnessed from clinical data. Patient and data privacy is paramount and requires a robust de-identification platform including de-identification of unstructured data at scale. The cloud provides the ability to be able to perform best-in-class de-identification.
To harness longitudinal data, the platform itself must be made complete with access to rich data across all modalities (clinical, molecular and imaging data). Addition of novel data types such as digital pathology and molecular biology helps provide an unprecedented, comprehensive 360-degree view of the patient’s story.
[Image courtesy of nference]
Data enrichment: harmonization and curation
Information is entered into the EMR in diverse forms, from variations in the units used to record a given value (body temperature measured in Celsius versus Fahrenheit) to variations in labeling due to the integration of different coding systems or even typographical errors. In short, the raw EMR contains data generated by the interactions of fallible human beings with data storage systems whose organizational scheme designs have evolved over time and can differ across clinical sites. As a result, the same kind of information can be stored in many different locations, under different labeling or in different formats, within the same EMR. If we want to analyze one metric across all patients, we first need to gather all records of that metric and standardize the way results are stored. Harmonization is a broad-scale effort to pursue this kind of data organization across all metrics in the EMR data.
The majority of EMR data exists in semi-structured or completely unstructured forms. Curation — transforming this data into structured labeled data — is a critical part of enabling artificial intelligence (AI) applications downstream. Coupling state-of-the-art technology with deep biomedical expertise to transform semi-structured data (augmented harmonization) and unstructured data (augmented curation) results in the largest labeled dataset in healthcare. This requires cloud-scale capabilities. Some examples include drug to phenotype, disease diagnosis, diagnosis date, disease location, and oncology biomarker status.
Data Science Platform
The cloud truly enables commoditization of algorithms to provide data science to the masses:
- Ready-made applications: Hyperscalers have added several AI capabilities specific to healthcare and life sciences that make it easy to consume these services without requiring deep knowledge of the science of AI/machine learning (ML)/deep Learning. For example, Google Cloud Platform provides Cloud Healthcare API, a pathway to intelligent analytics and ML capabilities. The other two of the big three cloud service providers offer similar capabilities: Amazon HealthLake, and Microsoft’s Azure for Health.
- AutoML, also known as code-free data science: The rise of the citizen data scientist means we can, with minimal subject matter expertise, bring our own data and have computers tell us what algorithms are best to answer our specific question. These algorithms don’t discriminate between protected classes and, further, tell us which features we should use when trying to predict an outcome without having to start from scratch. Each of the cloud providers offer significant advances in this space.
Scalable computing and advanced ML tools allow pioneers to keep pushing the envelope of what is possible. Innovators in this space favor a hypothesis-free approach to science over the status quo, hypothesis-driven approach. Instead of solving one problem at a time, we strive to develop generalizable and extensible models that can dramatically accelerate downstream hypothesis generation and holistic algorithm development.
The cloud truly enables the scale and flexibility of such an approach. The elasticity of the cloud provides the flexibility and freedom to operate at-scale, while being able to unabashedly experiment.
Vik Nagjee is the vice president of product at nference and serves as an advisor to Anumana Inc., a company created by nference and the Mayo Clinic. Previously CTO at several organizations, he was responsible for healthcare solutions, strategy and market development and oversaw product security and regulatory compliance to help ensure the security of information systems and patient health information.
The opinions expressed in this post are the author’s only and do not necessarily reflect those of MedicalDesignandOutsourcing.com or its employees.